
Texto de: Letícia Garcez
Introdução
A palavra RegEx é uma abreviação de Regular Expression, ou Expressão Regular se traduzirmos para o português. Este conceito é de extrema importância quando falamos de computação, e tem como função reconhecer padrões em textos.
Para fazer esse reconhecimento, uma RegEx é composta de vários símbolos que representam caracteres, grupos de caracteres, quantidades de um determinado caractere, entre outros, dispostos para definir a regra de reconhecimento de um padrão.
Conceitos básicos
Vamos começar entendendo o significado de alguns caracteres utilizados nas RegEx:
[ ]→ representa um grupo, sendo que os elementos digitados entre os colchetes representam os elementos do grupo, como em[abcde]{ }→ as chaves são utilizadas para indicar quantidade. Podemos especificar uma quantidade específica como{3}, uma quantidade mínima{5,}(5 ou mais) ou um intervalo{2,10}(entre 2 e 10)|→ o caractere pipe pode ser utilizado para indicar uma alternância entre dois símbolos, como na expressãoa | bonde tanto o caractereaquanto o caracterebpodem ser aceitos.→ o ponto representa um símbolo qualquer e é normalmente utilizado como uma espécie de coringa?→ o ponto de interrogação é um quantificador, ou seja, indica uma quantidade, e quando colocado ao lado de um símbolo representa zero ou uma ocorrências daquele símbolo. Já quando colocado ao lado de um grupo, representa zero ou uma ocorrência de algum dos elementos dentro do grupo+→ o símbolo de adição é um quantificador muito parecido com o ponto de interrogação e também pode ser utilizado ao lado de um símbolo ou de um grupo. No entanto, diferentemente do ponto de interrogação, esse símbolo representa uma ou mais ocorrências do elemento, ou seja, de uma até infinitas ocorrências.*→ O asterisco também é um quantificador e pode ser utilizado da mesma maneira que o símbolo de adição, com a diferença de que também irá reconhecer zero ocorrências do elemento em questão.
Além disso, existem alguns grupos comumente utilizados nas RegEx:
[a-z]→ reconhece as letras minúsculas[A-Z]→ reconhece as letras maiúsculas[0-9]→ reconhece os numerais de zero a nove[a-zA-Z]→ reconhece os caracteres de a até z independentemente se são maiúsculos ou minúsculos[a-zA-Z0-9]- reconhece as letras de a até z, tanto maiúsculas quanto minúsculas, e os números de zero a nove\\s→ representa o grupo dos caracteres espaço, que incluem indentações, espaços, etc.
Uma coisa importante que precisamos ter em mente é que alguns caracteres acentuados como "é", "ç", "ã", "ü", "í", "à", etc. não estão incluídos no conjunto de caracteres de a até z. Portanto, caso você precise trabalhar com este tipo de caractere na sua expressão regular, esses conjuntos não serão o suficiente para atender as suas necessidades e você terá de buscar por alternativas.
RegEx 101
Para entendermos melhor o que são as RegEx, vou utilizar nesse artigo um site chamado RegEx101 que você pode acessar clicando aqui.
Nesse site, podemos escolher qual especificação de implementação das RegEx queremos utilizar, bem como testar uma RegEx de maneira rápida. O site também oferece uma referência rápida sobre alguns recursos das RegEx e até mesmo uma explicação do que a sua RegEx faz no lado direito da tela, o que também é interessante.
Eu selecionei a implementação das RegEx da linguagem JavaScript e coloquei o texto abaixo como teste. Nesse texto temos alguns endereços de IP e alguns telefones fictícios para fazermos alguns testes.
192.168.0.1
+55 (00) 1234-5678
192.168.10.102
192.168.1041.102
192-168-0-102
192.168.0.125
+55 (00) 91234-5678
+55 (00) 912345678
Encontrando os IPs
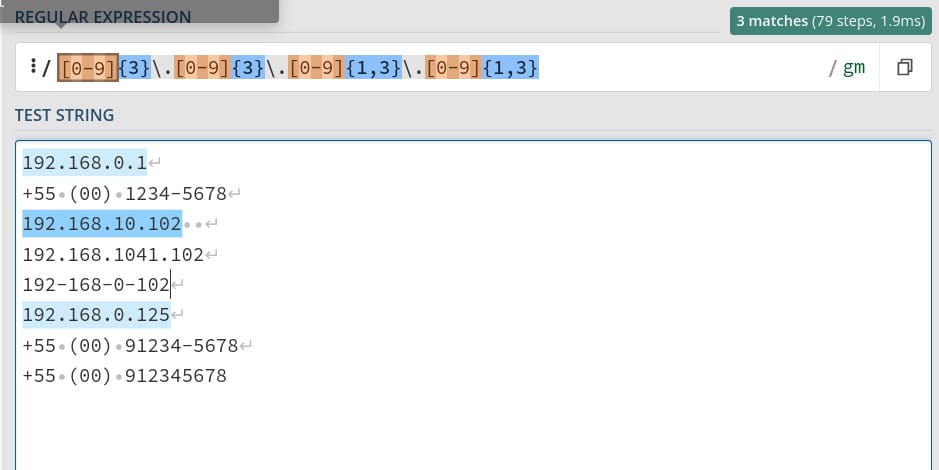
E agora podemos testar algumas expressões regulares, para, por exemplo, encontrar entre o texto de teste os IPs que possuem uma formatação válida. Sabendo que um IP tem o formato XXX.XXX.XXX.XXX, podemos usar a expressão [0-9]{3} para encontrar três números seguidos e podemos especificar depois disso o caractere ponto. Como o ponto é um caractere utilizado como símbolo nas RegEx, precisamos utilizar antes dele o caractere de escape \\ para que ele seja entendido como um caractere comum.
Como os dois primeiros grupos de números do endereço sempre terão 3 números, basta copiar essa expressão duas vezes para reconhecê-los e para reconhecer os dois últimos precisamos levar em consideração que estes podem ter de 1 a três ocorrências, então fazendo uma modificação no quantificador entre parênteses e repetindo acabamos novamente com a expressão [0-9]{3}\\.[0-9]{3}\\.[0-9]{1,3}\\.[0-9]{1,3} que irá reconhecer a formatação correta de um endereço de IP.
Encontrando números de telefone
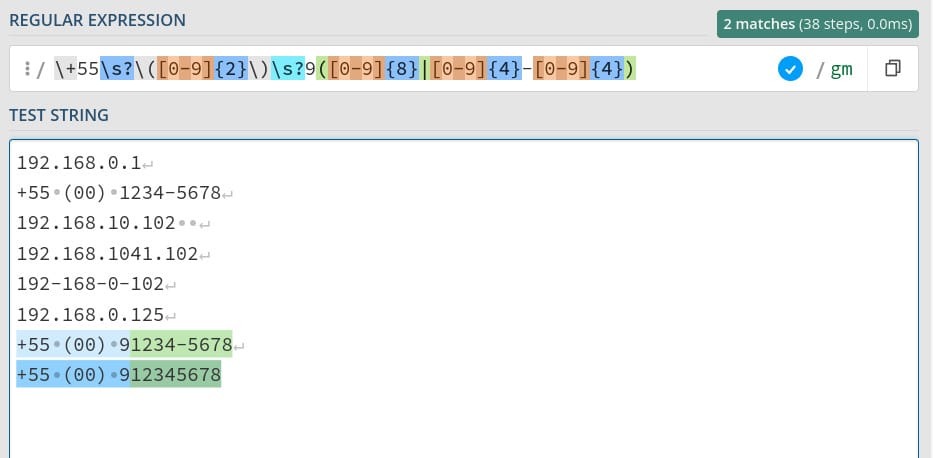
Outro teste que podemos fazer é para reconhecer os números de telefone da string de teste. Como todos os números dispostos começam com +55, podemos iniciar nossa expressão regular com \\+55 já que o símbolo de adição também precisará do caractere de escape. Depois disso, podemos ou não ter um espaço, então utilizaremos \\s? para haver o match de zero espaços, ou um espaço.
Com isso, temos que reconhecer o DDD que será especificado entre parênteses, e novamente temos caracteres especiais envolvidos na história: os parênteses. Por isso, precisaremos utilizar o caractere de escape tanto no abre parênteses quanto no fecha parênteses, e dentro dos parênteses podemos ter qualquer conjunto de dois números, o que faz com que precisemos da expressão \\([0-9]{2}\\)\\s? para fazer o match dos parênteses com o DDD e já considerar um possível espaço após os parênteses.
Com isso, podemos nos preocupar com o número de telefone em si. Ele sempre começará com o número 9, então podemos colocar o número 9 diretamente na nossa expressão e aí temos duas opções para o número ser válido. A primeira é termos oito números depois deste nove, e a segunda é termos quatro números, um hífen e mais quatro números. O primeiro caso pode ser encontrado com a expressão [0-9]{8} e a segunda com a expressão [0-9]{4}-[0-9]{4}, então basta utilizar o operador de alternância entre essas duas operações, mas para isso precisamos colocá-las entre parênteses, ou seja, ficamos com a expressão ([0-9]{8} | [0-9]{4}-[0-9]{4})
Juntando todas essas expressões, acabamos com a expressão \\+55\\s?\\([0-9]{2}\\) \\s?9([0-9]{8}|[0-9]{4}-[0-9]{4}) que irá reconhecer apenas os números de telefone válidos.
Considerações finais
Como você pode ter percebido, o uso de expressões regulares proporciona uma maneira muito atrativa para fazer o reconhecimento de padrões, porém conforme a complexidade do padrão que precisa ser reconhecido, a expressão pode ficar muito complexa, tanto do ponto de vista computacional quanto do ponto de vista de entendimento.
Não é incomum também que a utilização de expressões regulares impacte em um desempenho menor do que alternativas que não utilizem esse conceito, portanto sempre é preciso avaliar com cuidado se a utilização de expressões regulares será realmente a melhor opção para o problema que você deseja selecionar.