
Texto de: Marlliton Souza
Introdução
Os streams do Node.js são uma espécie de buffer que carrega dados, que não podem ser tipos primitivos do JavaScript, sob demanda. Um exemplo clássico de utilização de streams é um serviço de reprodução de filmes, onde, ao clicar no botão de play, o filme começa a ser exibido após o processamento das primeiras informações sobre a mídia chegarem a sua máquina, e conforme o filme vai sendo exibido, novas informações são enviadas para a sua máquina e processadas, permitindo que os próximos minutos do filme sempre estejam prontos para ser exibidos.
Como o Node.js consegue trabalhar com os dados sem carregá-lo por completo?
Um buffer consegue dividir qualquer dado em pequenos pedacinhos (chunks) e trabalhar com eles individualmente. Esses pedaços, passam por um “cano” ou “funil” (pipe). Em seguida, você pode processar esses dados fazendo o que quiser com eles. Os chunks fazem com que você evite o desperdício de memória e processamento, tornando tudo muito mais simples.
Exemplo prático
Imagine que você está lendo dados de alguma fonte e você quer armazenar esses dados em um arquivo csv, contudo, são milhares de linhas contendo informações. Tendo isso em mente, vamos simular aqui uma fonte de dados externa e depois converteremos esses dados para o formato csv. Um exercício bem simples, mas que fará com que você tenha uma visão mais detalhada dos streams. Você pode baixar o projeto completo clicando aqui, dessa forma você pode acompanhar a evolução do script para um melhor entendimento.
Readable stream
Criaremos antecipadamente, os dados a partir de uma readable stream, usando um for simples:
import { Readable } from "node:stream";
class ReadableStream extends Readable {
_read() {
for (let i = 0; i < 1e4; i++) {
// Gera 10 mil linhas de dados
const person = { id: randomUUID(), name: `marlliton ${i}` };
this.push(JSON.stringify(person));
}
this.push(null); // Informa para o Readable que os dados acabaram
}
}
new ReadableStream()
.pipe(
process.stdout // Writable stream, mostra/escreve dados no console
) Logo após executar o código acima, os dados são “jogados” no console de forma completamente desorganizada.
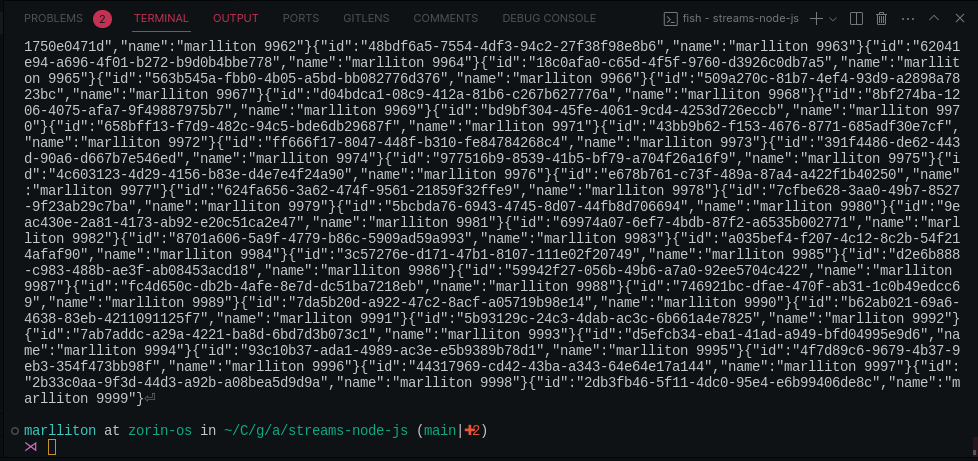
Desse modo, é muito difícil analisar os dados, então, precisamos transformar esses dados em um formato amigável, que seria no caso o csv.
Transform stream
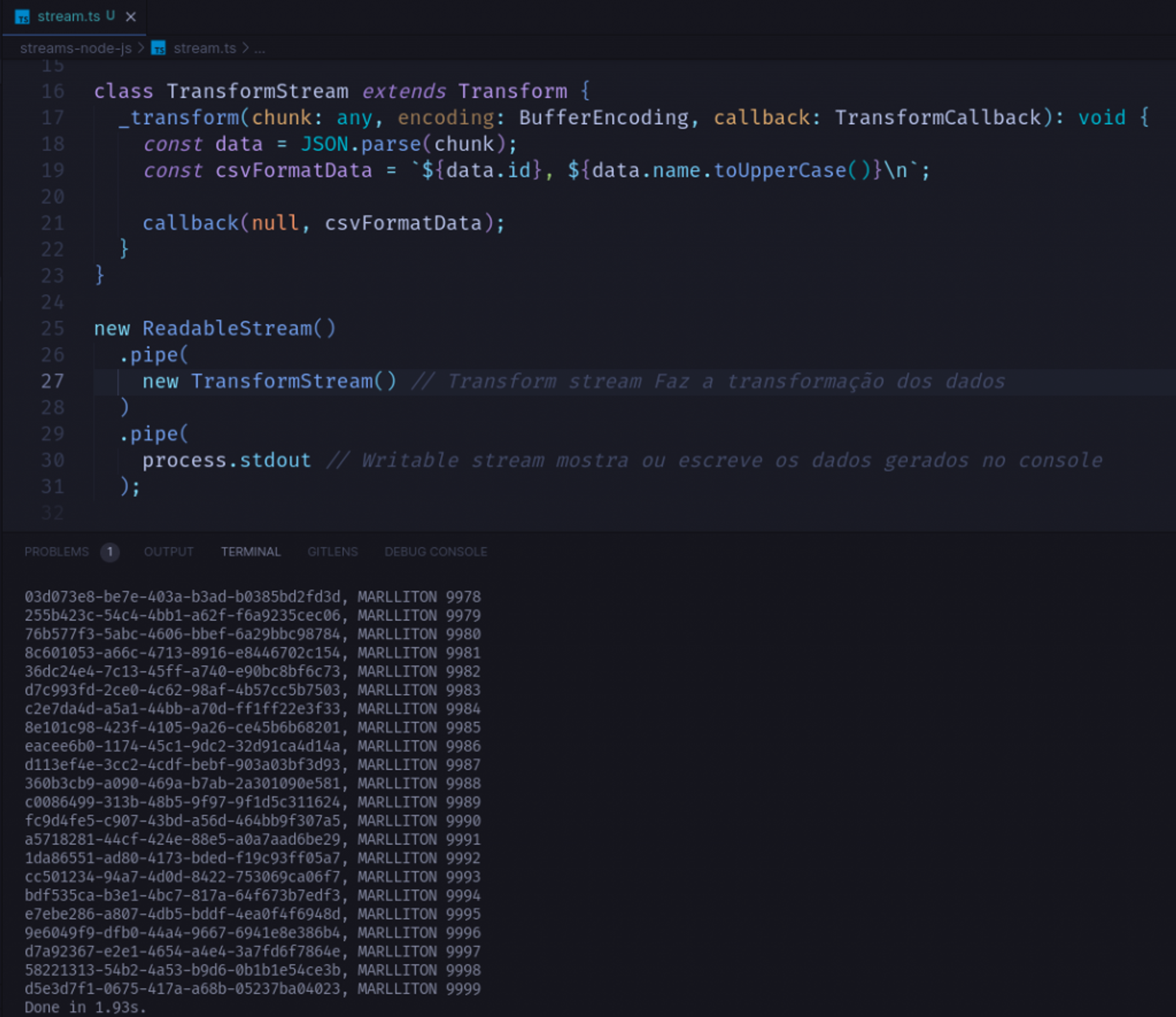
Usaremos a stream de transformação para modificar os dados conforme o formato desejado:
import { Transform } from "node:stream";
class TransformStream extends Transform {
_transform(chunk: any, encoding: BufferEncoding, callback: TransformCallback): void {
const data = JSON.parse(chunk);
const csvFormatData = `${data.id}, ${data.name.toUpperCase()}\n`;
callback(null, csvFormatData);
}
}
new ReadableStream()
.pipe(
new TransformStream() // Transform stream Faz a transformação dos dados
)
.pipe(
process.stdout
) Ao rodar o código acima, teremos o seguinte resultado:
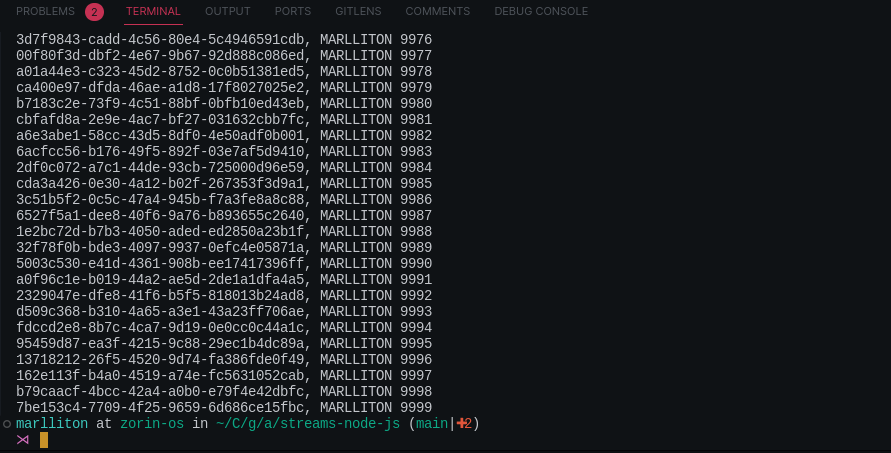
Agora, os dados podem ser compreendidos de uma forma muito fácil. Mas o que a função _transform faz e como ela funciona?
A função _transform recebe 3 parâmetros:
- Chunk: pedaço do dado que estamos processando.
- Encoding: é a codificação dos caracteres usada para interpretar o conteúdo do buffer (chunk). Você pode mudar o encoding, caso faça sentido.
- Callback: função que recebe um erro e o dado que acabamos de modificar.
Após a execução da transform stream, os dados estão no formato desejado, mas para podermos analisar todas as linhas de forma simples, precisamos salvar esses dados em algum arquivo csv.
Writable stream
Antes de reaumente salvar os dados em um arquivo vamos definir o cabeçalho do nosso documento. Para isso usaremos mais uma vez transform stream:
import { Transform } from "node:stream";
class SetHeaderCsv extends Transform {
counter: number = 0
_transform(chunk: any, encoding: BufferEncoding, callback: TransformCallback): void {
if (this.counter > 0) {
callback(null, chunk)
return
}
this.counter += 1
callback(null, 'ID,\t\t\t\t\tNAME\n'.concat(chunk))
}
}
new ReadableStream()
.pipe(
new TransformStream() // Transform stream Faz a transformação dos dados
)
.pipe(
new SetHeaderCsv() // Define o header do arquivo csv
)
.pipe(process.stdout) Ao passar por mais essa etapa de transformação, os dados passarão a ter um cabeçalho que identifica os campos como id e name, e o resultado será:

Depois disso, tudo que faremos é salvar os dados:
class WritableStream extends Writable {
private _path: string
private _stream: WriteStream
constructor(path: string) {
super()
this._path = path
this._stream = createWriteStream(this._path, 'utf8')
}
_write(
chunk: any,
encoding: BufferEncoding,
callback: (error?: Error | null | undefined) => void
): void {
console.log(chunk.toString())
this._stream.write(chunk, encoding, (err) => {
if (err) {
this.emit('error', err)
}
})
callback()
}
}
new ReadableStream()
.pipe(
new TransformStream() // Transform stream Faz a transformação dos dados
)
.pipe(
new SetHeaderCsv() // Define o header do arquivo csv
)
.pipe(
new WritableStream('meu.csv') // Writable stream escreve os dados gerados no arquivo "meu.csv"
) Essa classe recebe os pedaços de dados que já foram processados anteriormente, e os salva em um arquivo chamado meu.csv.
Com isso, nós poderíamos, facilmente, converter terabytes de dados sem que nosso aplicativo fique sem memória, ou que quebre por atingir todo o processamento. Contudo, se o seu hardware for realmente muito fraco, processar esses grandes volumes de dados, mesmo com o uso de streams pode ser problemático.
Apesar das streams diminuírem e muito a quantidade de memória/processamento utilizados para processamentos de dados, isso ainda pode ser um limitante caso a máquina seja muito modesta.
Conclusão
Por fim, ao executarmos o nosso script, ele gerará para nós um arquivo .csv com todas as informações:
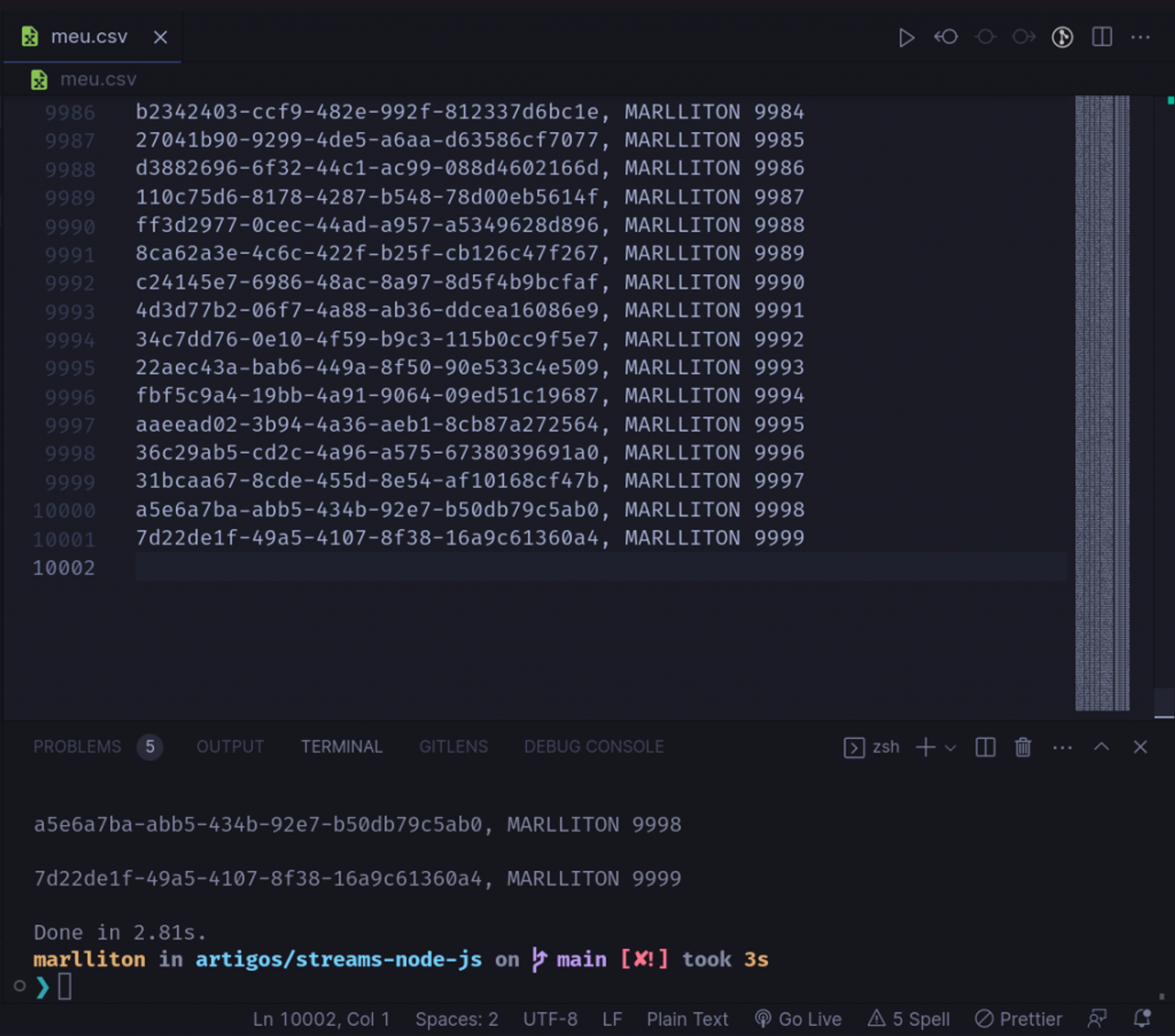
Você poderia fazer, o que quiser com esses dados antes de salvá-los sob demanda, no nosso exemplo apenas deixei em caixa alta.